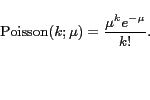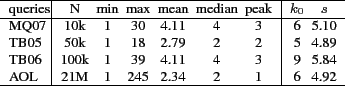Avi Arampatzis![]() Jaap Kamps
Jaap Kamps![]()
![]() Archives and Information Studies,
University of Amsterdam
Archives and Information Studies,
University of Amsterdam![]() ISLA, Informatics Institute,
University of Amsterdam
ISLA, Informatics Institute,
University of Amsterdam
Avi Arampatzis![]() Jaap Kamps
Jaap Kamps![]()
![]() Archives and Information Studies,
University of Amsterdam
Archives and Information Studies,
University of Amsterdam![]() ISLA, Informatics Institute,
University of Amsterdam
ISLA, Informatics Institute,
University of Amsterdam
Categories and Subject Descriptors:
H.3 [Information Storage and Retrieval]: H.3.3 Information Search
and Retrieval; H.3.7 Digital Libraries
General Terms: Measurement, Experimentation, Theory
Keywords: Query length, Power-law, Zipf's law, Transaction log analysis
From analysing query-logs, previous research has suggested that the
distribution of query lengths can be approximated with the
(generalized) Zipf's law
or a power-law [5,7]. The law
appears to fit well to the largest length observations ![]() (where
(where ![]() depends on the domain) but not to the whole sample. For
example, data show that the length frequency for web queries peaks at
depends on the domain) but not to the whole sample. For
example, data show that the length frequency for web queries peaks at
![]() rather than at single keyword queries, suggesting a
rather than at single keyword queries, suggesting a ![]() .
In the discrete case, the fraction of queries with length
.
In the discrete case, the fraction of queries with length ![]() is given by
is given by
Others, without empirical justification, modeled query lengths with a
Poisson distribution by setting its mean to the average query length
[1].
Using a Poisson distribution, in a population of queries with average
length ![]() , the fraction of queries with length
, the fraction of queries with length ![]() is
is
In this paper, we provide a model for query length. Beyond the
theoretical interest, such a model has also practical applications in
optimizing query cache size in search engines, in generating simulated
queries for efficiency testing, and for effectiveness evaluation
[e.g., 1].
Using several query data-sets, we confirm that the right tail of the
length distribution is better approximated with a power-law rather
than a Poisson, and introduce a truncated model. In the process, we
estimate the slope ![]() for English queries. Finally, we speculatively
explain why some data deviate from a power-law and what this may mean
for IR.
for English queries. Finally, we speculatively
explain why some data deviate from a power-law and what this may mean
for IR.
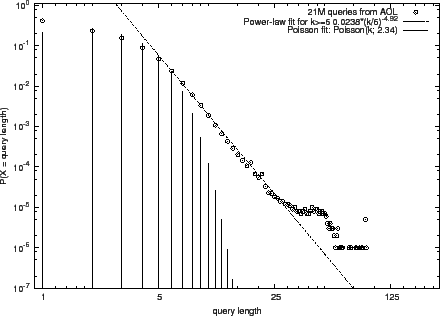
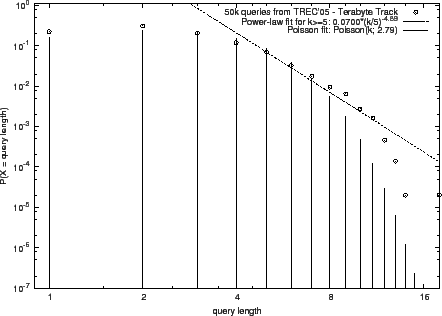
We applied the methods of Clauset et al. [2] to automatically
determine the scaling parameter, ![]() , using maximum likelihood
methods, and the lower bound,
, using maximum likelihood
methods, and the lower bound, ![]() , by minimizing the
Kolmogorov-Smirnov statistic. These values are in the final two
columns of Tab. 1 and the resulting distribution is
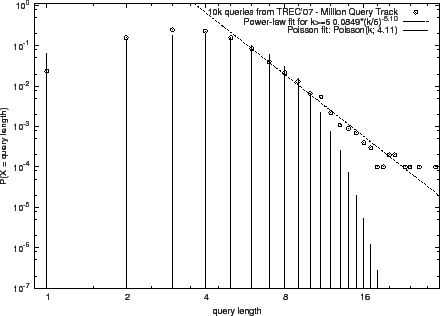
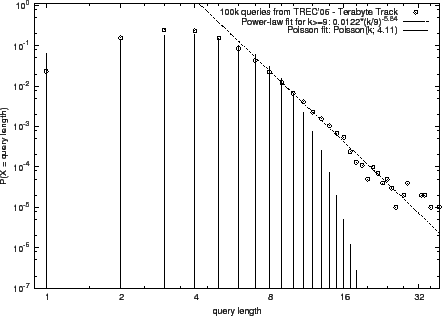
depicted in Fig. 1.1
, by minimizing the
Kolmogorov-Smirnov statistic. These values are in the final two
columns of Tab. 1 and the resulting distribution is
depicted in Fig. 1.1
The power-law model matches better the data in wider ranges of lengths
than the Poisson model. While the fits on MQ07 and TB06 are good,
there are some deviations in the right tails of the TB05 and AOL data.
The TB05 data may be better fitted with a similar distribution, namely a
power-law with an exponential cutoff [2]:
![]() . Note that Eq. 1 can be obtained from the latter for
. Note that Eq. 1 can be obtained from the latter for
![]() . This distribution is a common alternative because it
captures finite-size effects, e.g., earthquake magnitude data have the
same lack of tail due to the finite amount of energy in Earth's crust.
We can speculate that the data-set was probably created in a way that
there was a maximum query length imposed. The imposed maximum can be
indirect, e.g., a result of the maximum amount of effort and time
users are willing to put into formulating queries.
The "bump" in the AOL data seems of a technical nature possibly due
to a shift from typed queries to cut-and-paste queries; not knowing
whether and how these data are processed, we will not speculate any
further.
. This distribution is a common alternative because it
captures finite-size effects, e.g., earthquake magnitude data have the
same lack of tail due to the finite amount of energy in Earth's crust.
We can speculate that the data-set was probably created in a way that
there was a maximum query length imposed. The imposed maximum can be
indirect, e.g., a result of the maximum amount of effort and time
users are willing to put into formulating queries.
The "bump" in the AOL data seems of a technical nature possibly due
to a shift from typed queries to cut-and-paste queries; not knowing
whether and how these data are processed, we will not speculate any
further.
Since the bulk of queries concentrates at short lengths where a
power-law does not fit given the current indexing languages, it makes
practical sense to use a mix of truncated Poisson/power-law to model
query lengths. In such a practical model, lengths are
Poisson-distributed for ![]() and power-law-distributed for
and power-law-distributed for ![]() . The choice of
. The choice of ![]() depends on the specific domain, i.e., a
combination of features of the document collection, query/indexing
language, and pattern of use of the system.
depends on the specific domain, i.e., a
combination of features of the document collection, query/indexing
language, and pattern of use of the system.
Deviations of real data from the power-law may be explained by either finite-size effects or insufficient specificity of indexing terms. Studies in other fields, e.g., economics, have shown that deviations of data from the power-law at hand are usually an indication of inefficiencies in the system that the data come from. Pennock et al. [4] studied power-law distributions of numbers of web links and found that deviations of data from the power-law per category of websites correlate to how much competition is present in that category. The better the power-law fit, the more competitive the category. For query lengths, we have shown how a simple process of re-indexing on longer text fragments can "fix" some deviations, a fact that may point to inefficiencies in single-word indexing schemes.
Acknowledgments This research was supported by the Netherlands Organization for Scientific Research (NWO, under project # 640.001.501).
This document was generated using the LaTeX2HTML translator Version 2008 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -reuse 0 -no_footnode -numbered_footnotes -white -split 0 -long_titles 10 -show_section_numbers -antialias -antialias_text -address 'avi (dot) arampatzis (at) gmail' -html_version 4.0,latin1,unicode,utf8 -local_icons -no_navigation kto726-arampatzis.tex
The translation was initiated by Avi Arampatzis on 2009-10-16